
Training the LDA Model
With more than 9 million documents, the entire Wikipedia corpus takes a while to process and compile (or a larger budget!). The currently posted results for topic modeling are based on about 5.5 million documents, or a bit over 60% of Wikipedia (to be exact: 5578331 / 9019957 = 0.618).
On this corpus, I’ve trained five models. Here are the results for those models:
| model_ID | num_topics | alpha | eta | chunksize | passes | coh_topn | lda_runtime | c_v_coherence |
|---|---|---|---|---|---|---|---|---|
| 100 | 10 | asymmetric | 100000 | 1 | 10 | 12499.4541299343 | 0.5247517679 | |
| 101 | 10 | auto | 100000 | 1 | 10 | 15684.6514217854 | 0.5933546515 | |
| 102 | 20 | auto | 100000 | 1 | 10 | 8.4785871506 | 0.6304638499 | |
| 103 | 25 | auto | 100000 | 1 | 10 | 19074.6811187267 | 0.6301311693 | |
| 104 | 30 | auto | 100000 | 1 | 10 | 19897.7017846107 | 0.6059053268 |
The first model, Model 100, was run as a quick look to see some initial results. Its ‘alpha’ is set to ‘asymmetric’, which we’ve already shown runs faster but gets lower coherences compared to ‘auto’. Now we see the same pattern on this much larger corpus when we compare Model 100 to Model 101 above.
Out of all the models, Model 102 with 20 topics gets the highest Cv coherence, though Model 103 with 25 topics gets practically the same result. Even so, we’ll focus on Model 102.
Evaluating the LDA Model
How well did our model train? For an answer, we’ll evaluate two metrics: the proportion of documents that converged and the topic differences.
Document Convergence
Here is a plot of the proportion of documents that converged in each successive training iteration (i.e., for each chunk):
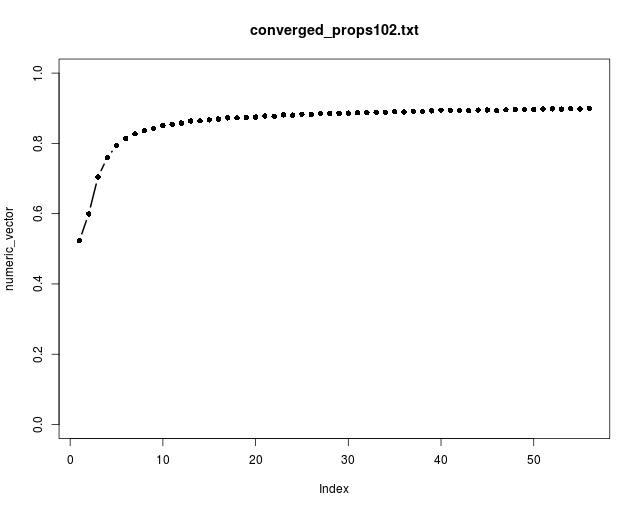
Ideally, every document would converge so that the curve would rise to 1 by the end of training. For our model it rises to about 0.90 at the last iteration. We would like it to be higher, but that’s fairly close to 1. The curve is still gradually rising at the end of training; if we ran another pass or two through the corpus, it might rise more, but we would have to tolerate a much longer running time.
Topic Differences
Here is a plot of the topic differences between successive training iterations (i.e., between chunks):
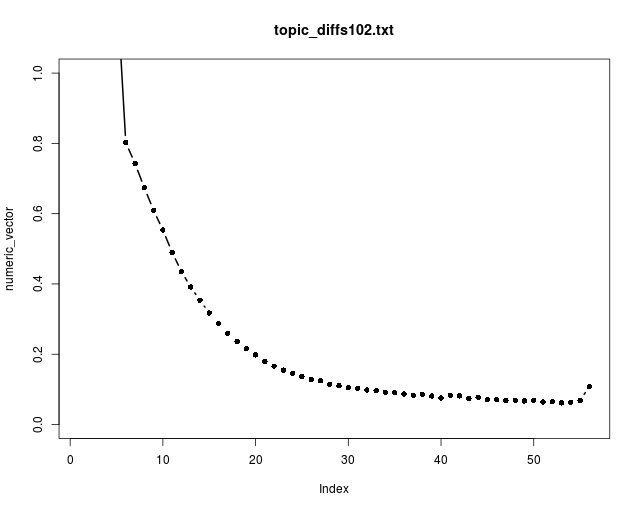
Ideally, we want to see this curve fall to zero. That would mean that there would be no differences between topics from iteration to iteration; the topics would have converged. In our case, the curve falls to about 0.07 (before mysteriously jumping up to 0.10 at the last iteration; perhaps there were few documents in the last chunk). As for the document convergence, we’d like to see it do somewhat better, but that’s good enough to use model.
Code
The code for training the LDA models is here.
The code for extracting the document convergences and topic differences from the training logs is here.
The code for plotting the document convergences and topic differences is here.